Datenanalyse mit Excel: Tipps zur effizienten Datenauswertung

Einführung in die Datenanalyse mit Excel
Zur Vorbereitung der Planung, zur Nachbereitung der Evaluation (= Reporting) ist eine Datenanalyse notwendig. Für das Management sind Antworten des Controllings auf Fragestellungen wichtig, wie:
- Was ist passiert?
- Warum ist es passiert?
- Was hat sich geändert?
- Was müssen wir tun?
- Was wird zukünftig passieren?
Wir leben in einem Umfeld, das sich ständig verändert, und zwar immer drastischer und immer schneller. Vorhersehbarkeit und Berechenbarkeit von Ereignissen nehmen in vielen Geschäftsmodellen rapide ab, Prognosen und Erfahrungen aus der Vergangenheit als Grundlage für die Gestaltung von Zukunft verlieren ihre Gültigkeit und Relevanz. Planung von Investitionen, Entwicklungen und Wachstum wird immer schwieriger. Dafür hat sich das Akronym VUCA etabliert. Umso wichtiger ist in diesem Umfeld eine Datenanalyse. Aber nicht nur eine der vergangenheitsbezogenen internen Daten ist wichtig, sondern auch eine Analyse der externen Daten, die einen Einfluss auf das Geschäftsmodell haben könnten (Predictive Analytics). Diese Analyse sollte zeitnah, unter Umständen in Echtzeit, korrekt und vollständig erfolgen. Dieser Ansprüche werden seit Jahren durch Business-Intelligence-Tools erfüllt. Waren diese Tools früher nur duch Experten bedienbar, hat sich in den letzten Jahren der Ansatz des Self(-Service) BI (z.B. Microsoft PowerBI-Desktop) durchgesetzt. Self-Service BI (SSBI) gestattet es verschiedenen Abteilungen innerhalb eines Unternehmens, auf die Unternehmensdaten zuzugreifen und selbstständig Analysen oder Reports zu erstellen.
Wichtige Voraussetzung dafür ist die Sicherstellung der Datenqualität durch eine vereinheitlichte Datenquelle und eine gute Datenqualität. Mit Datenqualität ist die Eignung von Daten für eine bestimmte Nutzung bei vorgegebenen Verwendungszielen gemeint. Eine gute Datenqualität zeichnet sich aus durch:

- Zuverlässigkeit, Richtigkeit und Konsistenz
- Vollständigkeit, Genauigkeit und Relevanz
- Aktualität und keine mehrspurige Erhebung
- Einheitlichkeit und Eindeutigkeit,
- keine Redundanzen der Daten
Dafür wird der Begriff «Single Source of Truth» (SSOT) verwendet. Damit wird ein allgemeingültiger Datenbestand beschrieben, der korrekt ist und auf den man sich verlassen kann. Single Source of Truth ist vor allem dann wichtig, wenn Daten in verschiedenen IT-Systemen redundant gehalten werden. Die Daten aus den verschiedenen Quellensystemen können in einem Data Warehouse vereint und zur Analyse zur Verfügung gestellt werden. Zur Auswahl einer geeigneten Data-Warehouse-Applikation bieten BARC2/Gartner gute Übersichten zu den Anbietern. KMU können aber auch mit Microsoft-Produkten gute Lösungen mit MS Access und Power Pivot erstellen, sofern die Datenqualität gesichert ist! Dann kann eine Datenanalyse mit Excel-Features durchgeführt werden.
Excel-Features für Datenanalyse und BI
Excel bietet für die Datenanalyse und auch für das Thema Self-Service BI etliche Features an, die viele Möglichkeiten bieten. Diese Features sollen nun vorgestellt und beschrieben werden. Diese sind:
- Pivot-Tabelle
- Power Query
- Power Pivot
- statistische Funktionen
- Predictive Analytics AddIn (z.B. Bert)
Pivot-Tabelle
Eine Pivot-Tabelle strukturiert in Tabellenform Daten, fasst sie zusammen und ermöglicht deren Auswertung. Seit die Pivot-Tabelle mit der Version Excel 5.0 eingeführt wurde, ist sie für Controller ein unverzichtbares Werkzeug. Für die Erstellung einer Pivot-Tabelle sind nur wenige Klicks notwendig, um Daten mit geringem Aufwand zu strukturieren, zu verdichten und zu analysieren, ohne die Ausgangsdaten durch Sortieren, Filtern usw. zu verändern.
Pivot-Tabellen machen das Erstellen komplexer Verknüpfungen oder Formeln innerhalb von Tabellen überflüssig. Änderungen in einer Pivot-Tabelle haben keine Aktualisierung der Originaldaten zur Folge. Damit erfüllt die Pivot-Tabelle das wichtige Prinzip der Datenkonsistenz.
Der Einsatz von Pivot-Tabellen ist immer dann sinnvoll, wenn eine Datenquelle (z.B. eine grosse Tabelle mit vielen Daten) ausgewertet werden soll und nicht alle Spalten (Felder) dafür benötigt werden.
Merkmale einer Pivot-Tabelle
- Sämtliche Daten stammen aus einer Ursprungstabelle.
- Pivot-Tabellen fassen Daten zusammen und stellen sie in aggregierter Form dar.
- Ihre Struktur besteht aus mehreren Bereichen. Diese Bereiche können beliebige Felder der Ausgangstabelle aufnehmen.
- Der Anwender bestimmt, nach welchen Feldern gruppiert wird und welche Felder angezeigt werden sollen. Mit Feldern sind in der Logik von Datenbanken bei Excel-Tabellen die Spalten gemeint.
- Eine Pivot-Tabelle aktualisiert sich nicht nach jeder Änderung der Ausgangsdaten. Dazu muss die Pivot-Tabelle manuell oder per Voreinstellung beim Öffnen der Datei automatisch aktualisiert werden.
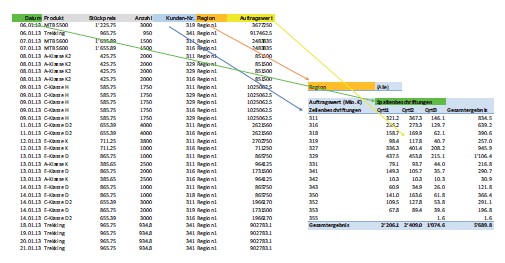
Mit sogenannten Zeilen- und Spaltenfeldern werden die Ausgangsdaten nach dem jeweils ausgewählten Feld gruppiert. Die Gruppierung erfolgt entweder zeilen- oder spaltenbasiert. Datenfelder stellen die Informationen an den Schnittpunkten von Zeilen und Spalten dar. Über Funktionen wie SUMME() oder ANZAHL() erfolgt die Ermittlung eines Datenwerts. Mit Seitenfeldern ist das Einschränken von Datensätzen auf bestimmte Werte möglich (siehe Abbildung hier).
Passende Produkt-Empfehlungen






Voraussetzungen für das Erstellen einer Pivot-Tabelle
Die Ausgangsdaten für eine Pivot-Tabelle liefern («Intelligente») Tabellen oder externe Datenquellen mittels Power Query. Wichtig ist, dass jeder Datensatz in einer eigenen Zeile steht. In der obersten Zeile müssen die Spaltentitel als Beschriftungen eingetragen sein. Jede Spalte sollte einen eigenen Titel haben. Damit die Pivot-Tabelle die Zusammenhänge zwischen den Daten versteht, sind Leerzeilen innerhalb der Listen oder der Tabellen zu vermeiden.
Vorteile durch den Einsatz von Pivot-Tabellen
- übersichtliche und strukturierte Darstellung der Ausgangsdaten
- schnelle und einfache Zusammenfassung und Auswertung grosser Datenmengen ohne spezifische Datenbank- oder SQL-Kenntnisse
- einfache Analysemöglichkeiten, ohne Daten in andere Tabellen umzukopieren oder komplexe Formeln und Bezüge zwischen Feldern und Tabellen anzuwenden, darüber hinaus sind sie
- flexibel an viele verschiedene Auswertungsanforderungen anpassbar
Power Query
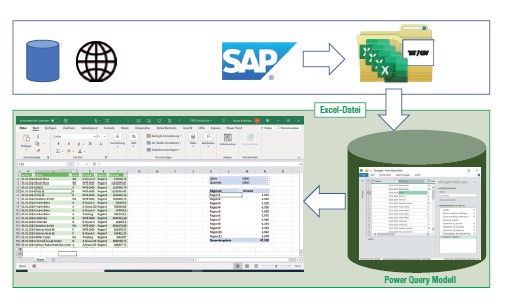
Unabhängig davon, ob Sie Business Intelligence, nur eine einfache Datenanalyse betreiben wollen, ist das seit Excel 2013 existierende Feature Power Query ein «must have» für Controller. Mit Power Query können Sie automatisiert externe Daten in Ihre Excel-Modelle importieren, dabei die Daten so verändern (Struktur, Datentypen usw.), dass sie in eine Ihren Anforderungen entsprechende Zielstruktur geladen werden können.
Zu den Datenquellen gehören (keine vollständige Aufzählung):
- Datenbanken (MS Access, SQL Server, Oracle, IBM)
- Dateien (PDF-, Text- und Excel-Dateien, [Sharepoint-]Ordner!)
- Online (Cloud, WEB, SAP HANA, Share-Point, Salesforce, Hadoop u.v.m.)
Als Ergebnis eines Power-Query-Modells erhalten Sie eine «intelligente» Excel-Tabelle oder eine Verbindung, die als Schnittstelle für eine Pivot-Tabelle genutzt werden kann.
Dabei wird jeder (Transformations-)Schritt protokolliert und ist auch nach Jahren noch nachvollziehbar. Die Befehle in den Menüs des Power-Query-Editors sind sehr anwenderfreundlich formuliert.
Die Stärke von Power Query liegt in dem Laden und Transformieren von Daten. Wenn es darum geht, die Daten zu berechnen, zu aggregieren oder zu analysieren, dann sollten die Daten mit einem Klick an ein Power-Pivot-Modell übergeben werden. Dennoch ein Hinweis auf die Schnittstelle zu SAP HANA (Excel 365). So können Daten in Echtzeit verarbeitet werden, wenn SAP HANA als Datenquelle genutzt wird (siehe Abbildung hier).
Power Pivot
Power Pivot scheint aufgrund der Bezeichnung eine sehr leistungsstarke Pivot-Tabelle zu sein. Tatsächlich ist sie eine Integration der Micro soft SQL Server Analysis Service (SSAS) in Excel. SSAS ist ein multidimensionales Online Analytical Processing (OLAP) und Data Mining Tool von Microsoft. Es ist seit der Microsoft SQL-Server-Version 2000 Bestandteil der SQL-Server-Software. Technisch gesehen erstellen Sie mit Power Pivot ein Datenmodell, das als lokaler OLAP-Cube generiert wird und mit dem Sie grosse Datenmengen (32-bit-Variante von Excel maximal 2 GB RAM, 64-bit mehr) analysieren können. Das Ergebnis wird in eine Pivot-Tabelle ausgegeben oder kann mit den CUBE-Funktionen von Excel genutzt werden.
Mit Power Pivot können Sie Daten seit der Version Excel 2010 aus Datenbanken, MS Analysis Service, Text- und Excel-Dateien in ein Datenmodell übernehmen.
Mithilfe von DAX-Funktionen (Data Analysis EXpressions) können Sie Berechnungen (Measures) erstellen, die als Teil des Datenmodells gespeichert werden. Bei Aktualisierungen des Modells werden diese Measures im Datenmodell aktualisiert und nicht wie bei der «klassischen» Pivot-Tabelle im Pivot-Cache. So sorgt der Einsatz von DAX-Funktionen für eine bessere Performance und ermöglicht überhaupt erst die Analyse von Millionen von Datensätzen! Interessant sind dabei besonders die Funktionen der Zeitintelligenz. Sie erlauben das Aggregieren (z.B. Year-to-Date) und Vergleichen von Daten über einen in der Power-Pivot-Tabelle definierten Zeitraum (z.B. die Funktion SAMEPERIODLASTYEAR).

Wenn allerdings die Daten nicht in den notwendigen Strukturen (Tabellen) aus den Datenquellen bezogen werden können, müssen Sie zunächst Power Query verwenden und das Ergebnis der Transformation an Power Pivot übergeben (nur ein Klick!). Power Pivot ist auch Teil der Power-BI-Plattform, die Erfahrungen mit Power Pivot aus dem Umgang mit Excel-Modellen lassen sich daher gut in Power-BI-Projekte einbringen.
Die Datenanalyse (nur Excel 365) analysiert alle Daten einer Tabelle, deren Zusammenhänge und identifiziert Muster in der Veränderung von Daten. Dieses Feature soll dabei helfen, Trends, Muster und Ausreisser in einem Datensatz schneller identifizieren zu können und den Analyseaufwand zu verringern. Die Ergebnisse werden automatisch in kurzer Zeit in Form von Diagrammen und Kommentaren in einem speziellen Fenster angezeigt. Vergleichbare Ergebnisse würden mit den Statistikfunktionen und dem Add-in für die Regessionsanalyse erheblich länger dauern und aufwendiger sein (siehe Abbildung hier)!
Statistische Analyse
Für eine statistische Analysen bietet Excel ca. 110 Funktionen an. Die sind technisch gesehen einfach zu bedienen, erfordern aber statistisches Know-how. Generell kann man drei Teilbereiche der Statistik unterscheiden:
- Mit Verfahren der deskriptiven Statistik wird versucht, Daten zu beschreiben. So können auch Fehler in den Daten erkannt werden. Dazu werden im Rahmen von Excel- Funktionen zur Berechnung von z.B. Mittelwert, Varianz Standardabweichung, Maximum, Minimum, Ränge, Quartile und Häufigkeiten angeboten. Damit kann die Verteilung und Lage eines Merkmals ermittelt werden.
- Die Ergebnisse einer Datenanalyse sind nicht durch Fehlerwahrscheinlichkeiten abgesichert. Dies kann durch die Methoden der induktiven Statistik erfolgen, sofern die untersuchten Daten den dort unterstellten Modellannahmen (Hypothesen) genügen. Dafür gibt es im Rahmen von Excel Hypothesentests (Gauss-Test, T-Tests, F-Test, Student-Test).
- Mit Verfahren der explorativen Statistik sollen bisher unbekannte Strukturen und Zusammenhänge in den analysierten Daten gefunden und hierdurch neue Hypothesen generiert werden. Diese auf Stichprobendaten beruhenden Hypothesen können dann im Rahmen der induktiven Statistik mittels wahrscheinlichkeitstheoretischer Methoden auf ihre Allgemeingültigkeit untersucht werden. Excel bietet hierfür hauptsächlich grafische Unterstützung an (Box-Plot-Diagramm, Histogramm, Punkt-XY-Diagramm und Treemap).
- Ausserdem stellt Excel statistische Modelle für eine lineare und nichtlineare Regressionsanalyse sowie Trendanalysen zur Verfügung. Varianzanalysen mit einem oder mehreren Faktoren, Korrelationsanalyse nach Pearson und die Fourier-Transformation (Zeitreihenanalyse) sind ebenfalls möglich.
- Für die Wahrscheinlichkeitsberechnungen bietet Excel Funktionen zur Generierung von Zufallszahlen, Stichprobenziehungen und von Permutationen an (siehe Abbildung hier).
Predictive Analytics AddIn (z.B. Bert)
Möchte man Excel auch für Predictive Analytics nutzen, so ist das mit dem angebotenen Funktionsumfang nur bedingt möglich. Excel bietet beispielsweise kein Verfahren für Random Forest (ein aus mehreren unkorrelierten Entscheidungsbäumen bestehendes Klassifikations- und Regressionsverfahren), keines für die Warenkorbanalyse und keines für eine Segmentierung. Dieses müsste mit Excel-Technik erst erstellt werden, was wie bei Verfahren zur Monte-Carlo-Simulation prinzipiell möglich, aber aufwendig ist.
Daher ergibt es Sinn, hier den Funktionsumfang von Excel um ein Add-in namens BERT zu erweitern. Mit diesem Add-in können die gewünschten Funktionalitäten für Predictive Analytics mithilfe der Sprache R selbst programmiert werden. Die Sprache R kann übrigens auch für Anpassungen von Power-BI-Desktop verwendet werden.
Ist die Datenanalyse mit Excel noch zeitgemäss?
Auf jeden Fall! Die Power-Tools ermöglichen die Analyse von Daten jenseits der Grenze von 1,5 Mio. Datensätzen. Für viele statistische Verfahren gibt es einfach anzuwendende Funktionen. Sind die anzuwendenden statistischen und mathematischen Verfahren komplexer, steigt auch der Aufwand der Modellerstellung in Excel und die Gefahr von Fehlern. In diesen Fällen ist zu überlegen, ob Excel nicht um Add-ins erweitert und so der Umfang erweitert wird. Frei nach IKEA: Entdecken Sie die Möglichkeiten von Excel, aber die richtigen!






{kind=link}
{kind=link}